背景
传统深度神经网络取得了一定的成功但是有一个局限性,就是输入输出必须是固定纬度的向量,无法进行序列到序列的学习。Seq2Seq模型是一个端到端的通用框架,通过利用RNN模型,将一个序列翻译到另外一个序列,并在机器翻译、对话系统、语音识别、自动文摘等问题取得成功应用。
模型
顾名思义,就是将一个输入序列翻译成另外一个序列。输入输出序列长度可以不同。
Seq2Seq由一个encoder和一个decoder构成,encoder把观测样本X编码成一个固定长度的隐变量Z,decoder把隐变量Z解码成输出序列Y。
其中,encoder和decoder都是一个RNN模型。
RNN
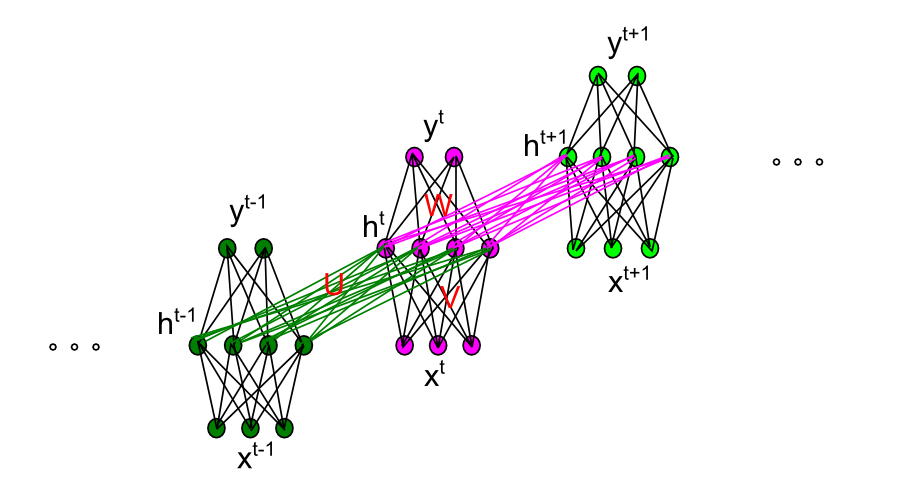
RNN模型是应用在序列数据上的深度神经网络。 给定序列\((x_1,x_2,...,x_N)\),RNN通过如下方式计算出输出序列\((y_1,y_2,...,y_N)\):
\[\begin{align} h^t & = f(x^tV + h^{t-1}U + b_h) \\ y^t & = g(h^tW + b_y) \\ \end{align}\]由于RNN因为存在梯度消失和爆炸现象,导致无法解决长距离依赖问题。为了解决该问题,出现了LSTM/GRU模型。
encoder-decoder 模型
假设训练集中有N个输入输出序列对\((X,Y)\),其中\(X=(x_1, x_2, ...,x_T),Y=(y_1,y_2,...,y_{T'})\)
模型的对数似然函数是
\[L=\frac{1}{N} \sum_{i=1}^N logp_{\theta}(y_n|x_n)\]其中,\(\theta\)是模型参数
\[p(y_n|x_n)=p(y_1,...,y_{T'}|x_1,...,x_T)=\prod_{t=1}^{T'}p(y_t|v,y_1,...,y_{t-1})\]其中, \(p(y_t \vert v,y_1,...,y_{t-1})\) 是一个定义在整个词库上的softmax函数
在预测阶段,找到最可能的翻译序列作为输出序列。
\[\tilde y = argmax_{y} p(Y|X )\]下面介绍两种常见的encoder-decoder模型
Google提出如下的encoder-decoder框架
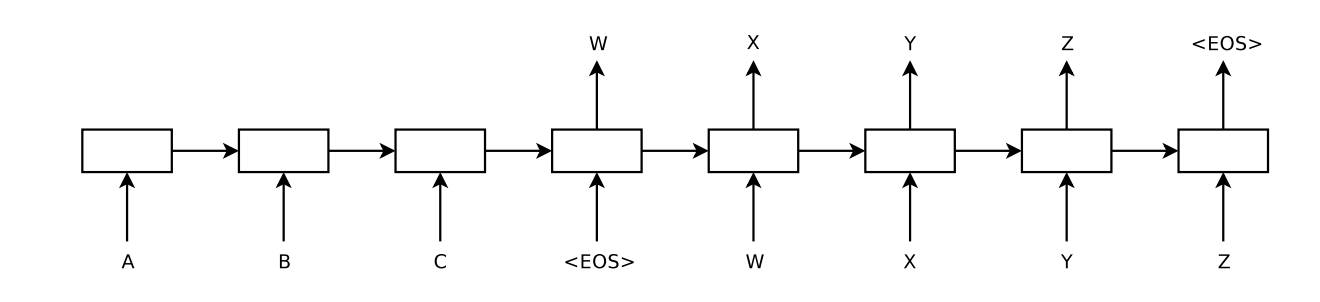
在编码阶段,使用一个深层LSTM对输入序列进行编码,将最后时刻的隐含状态\(W\)作为输入序列的语义表示。
在解码阶段,使用另外一个深层LSTM预测每个时刻的输出,其中,使用\(W\)作为初始时刻的隐含状态。
EOS作为序列的结束符(End Of Sequence)
decoder阶段,t时刻的隐含状态计算方法如下:
\[p(h_t)=f(h_{t-1}, y_{t-1})\]即t时刻的隐含状态仅和前一个时刻的隐含状态和输出状态相关。
Cho等人提出如下的encoder-decoder框架,该论文首次提出了GRU模型,并使用GRU模型进行编码和解码。
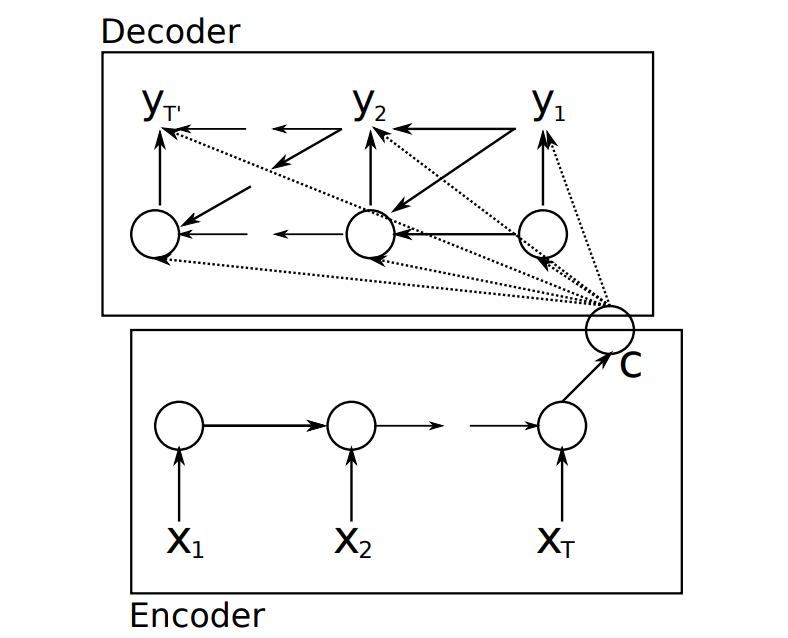
decoder中t时刻的隐含状态如下:
\[p(h_t)=f(h_{t-1}, y_{t-1},v)\]即t时刻的隐含状态除了和前一个时刻的隐含状态和输出状态相关以外,也和encoder阶段输出的编码向量v相关。
Attention 注意力模型
原始的encoder-decoder模型把输入序列的所有信息都压缩成一个固定长度的向量中,难以处理长句子。 [Bahdanau][3]等人提出注意力机制来解决该问题。
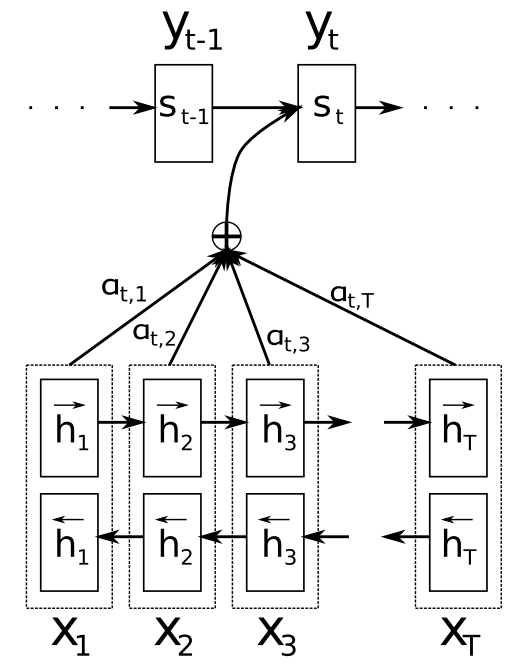
在上图中,encoder阶段使用双向RNN。该RNN对每个单词都生成一个隐含状态\(h_t\),论文中称为annotation,其实是双向RNN的隐含状态,将正向RNN和反向RNN的隐含状态连接在一起形成。
因为使用了双向RNN,\(h_j\)就同时包含了前方和后方时刻的信息.
在decoder阶段,上下文向量作为这些标注向量的线性组合。
在解码阶段,t时刻的隐含状态如下:
\[p(s_t)=f(s_{t-1}, y_{t-1}, c_t)\]单词的输出概率:
\[p(y_t\vert y_1,...,y_{t-1},x)=g(y_{t-1},s_t, c_t)\]attention weight
\[\alpha_{tj}=\frac{exp(e_{tj})}{\sum_{k=1}^{T_x} exp(e_{tk})}\]context vector
\[c_t=\sum_{j=1}^{T_x} \alpha_{tj}h_j\] \[e_{tj}=a(s_{t-1},h_j)\]\(e_{tj}\)称为alignment model,表示输入序列中位置j处的单词和输出位置中的t时刻的单词匹配的程度. 或者可以理解为输出训练中的单词i由输入序列中的单词j进行翻译的概率。
\[h_j=[\overrightarrow{ h}_j^T ; \overleftarrow{h}_j^T ]^T\]这里,a表示如下:
\[a(s_{i−1},h_j) = v_a^T tanh (W_as_{i−1} +U_ah_j)\]即一个单层的感知机模型,该模型和seq2seq的其他部分一起使用梯度下降进行优化。
其他trick
1.预测阶段如何找到最可能的输出序列
主要有greedy,sampling和beam-search 三种类型
- greedy算法
即每次选取概率最大的单词作为预测单词
示意图如下:
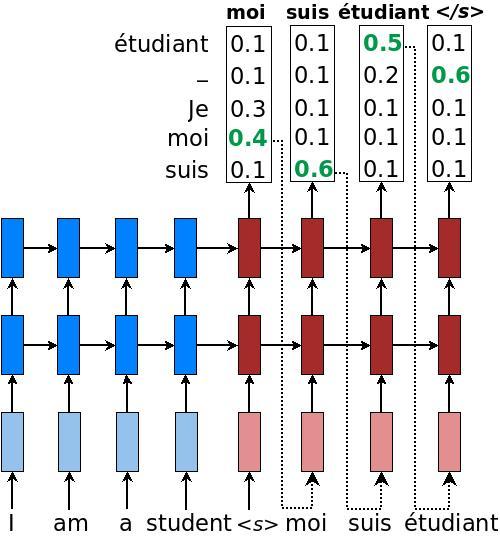
- beam search
相对贪婪算法,进一步增大搜索空间,在翻译时维护一个top候选的候选翻译序列集合。
beam的大小称为beam width,一般10就足够了
以beam_size = 2 为例
在解码时:
1: 生成第1个词的时候,选择概率最大的2个词,假设为a,c,那么当前序列就是a,c
2:生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,然后从其中选择2个得分最高的,作为当前序列,假如为aa cb
3:后面会不断重复这个过程,直到遇到结束符为止。遇到结束符时从beam中删除,加入到候选集中。最终输出2个得分最高的序列。
Google使用beam search找到最可能的翻译序列
- sampling
2.将输入序列逆序进行编码(encoder)
假设输入序列是\(a,b,c\),对应的输出序列是\(\alpha, \beta, \gamma\), 那么在编码阶段,RNN接受的输入序列变成\(c,b,a\),这样,\(a\)离\(\alpha\)更近,\(b\)离\(\beta\)更近…, 这样更便于SGD进行优化
3.RNN种类
seq2seq中的RNN可以有如下不同:
方向性: 单向、双向
深度: 单层、多层
RNN类型: 原始RNN、LSTM、GRU
实现
- bucket
先设定一个bucket列表,每个bucket中规定该bucket的输入序列的长度和输出序列的长度
然后将每个输入输出对放置到对应的bucket中.对于长度不满足的序列则进行对齐(padding)
tensorflow中已经实现了dynamic_rnn,可以不需要进行bucket.
- sampled softmax loss
在训练的decoder阶段,需要计算输出单词为词表中任意一个单词的概率,这是一个softmax。 在词表比较大时这样一个softmax计算比较耗时,于是出现了sampled softmax loss方法。
参考:
1.Sequence to Sequence Learning with Neural Networks
2.Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
3.NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
6.bucket
7.On Using Very Large Target Vocabulary for Neural Machine Translation
8.https://www.tensorflow.org/extras/candidate_sampling.pdf